
ISIE Webinar: Data-free models
Last Monday I presented a webinar to the ISIE Life Cycle Sustainability Assessment Section about using Antelope to create and share data-free LCA models. You can watch the webinar here.
The presentation had three main sections:
An introduction to modeling with fragments;
An overview of how I use Antelope software to maintain a running material-flow based LCA study for CATRA;
A walkthrough of the “hot shower” demo that I introduced at ISSST 2025.
Here is a link to the slides from that session
Since the webinar, I revised the jupyter notebook to include a lot more discussion about how the software works and what it’s doing. I also added a demonstration of how to use antelope-reports to extract data into a dataframe or a chart.
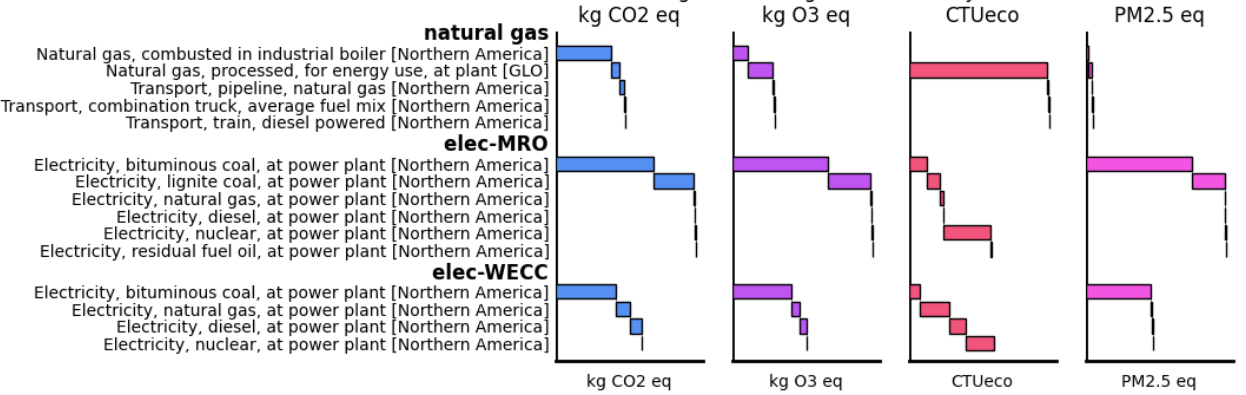
Waterfall chart showing contribution analysis for water heating (USLCI)
Hot Shower Energy Modeling
The meat of the demo concerns the development of a model for the impacts of heating water for a shower. I start by constructing a model for heat demand based on the duration of the shower, water flow rate, temperature increase, and heat capacity, ending with a “heat input” node. Then I anchor that node to two different models for water-heating, one using natural gas with an efficiency of 65%, the other using electricity with an efficiency of 90%. The model is built without accessing any life cycle inventory data at all.
The demo goes on to discuss the role of observation in specifying a model. Observation is the term for when a modeler encodes real-world information into an LCA model. The real-world information includes:
physical properties of real-world flows;
the exchange value for each link;
the upstream data source that describes each flow that crosses the foreground system boundary.
These observations also constitute the locus of private data required to construct and compute the model. Models can be shared while omitting some or all of this information, rendering them data-free.
Linking to data in the cloud
The Hot Shower demo runs without using any LCI data on the local computer. Instead, it obtains all the data for free from an Antelope xdb server hosting USLCI and TRACI. The initial modeling activity is done using a guest account, but for multi-indicator analysis a [free] authenticated user account is required.
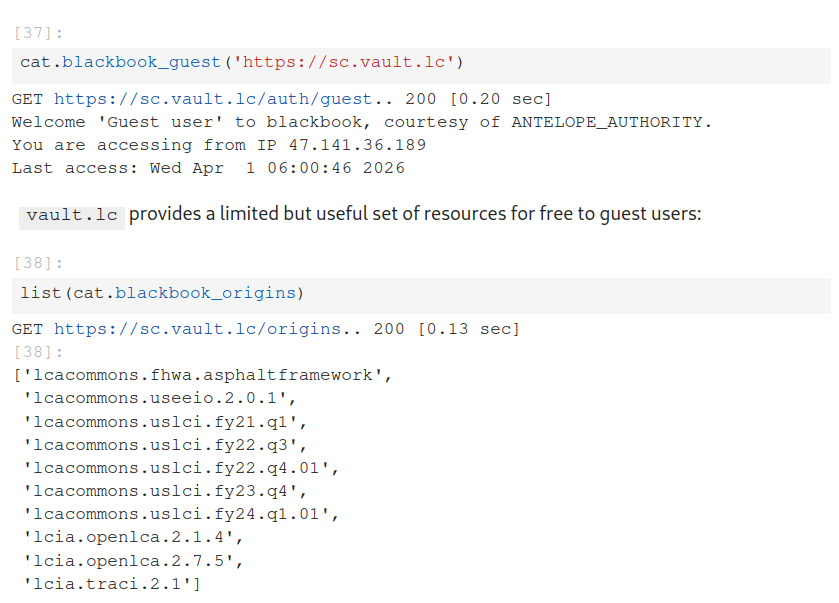
Accessing LCI data for free via blackbook
Contribution Analysis
The foreground modeling environment provides a way to expand linked activities, one level at a time, to obtain detailed information and also to make foreground changes that override the background defaults.
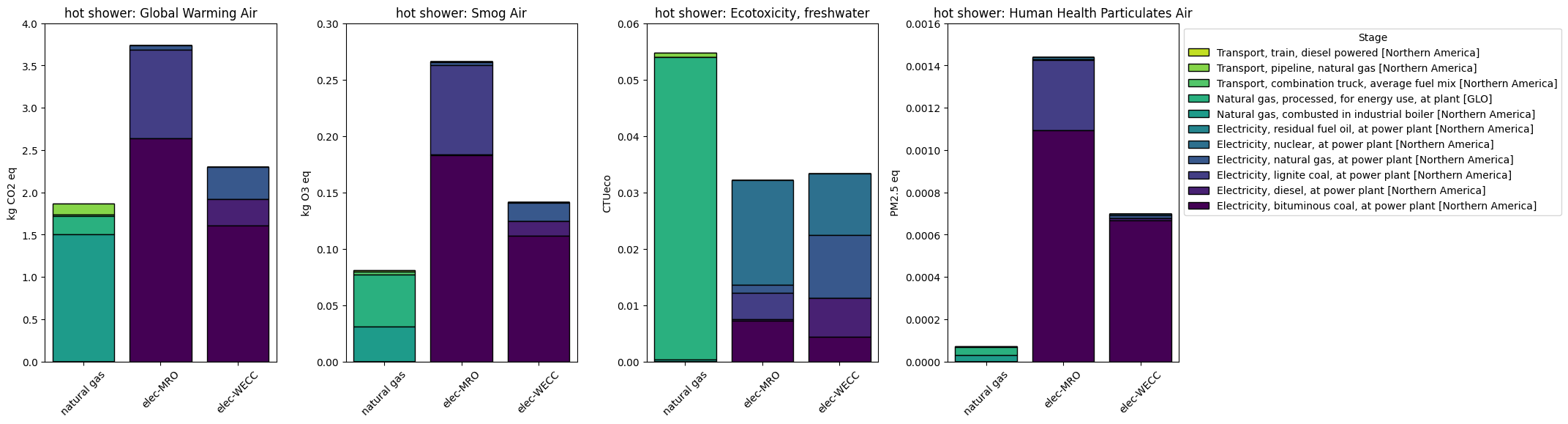
Contribution analysis, shown another way
Using traversal parameters, the results can be aggregated without altering the model, limiting what a given user can see.
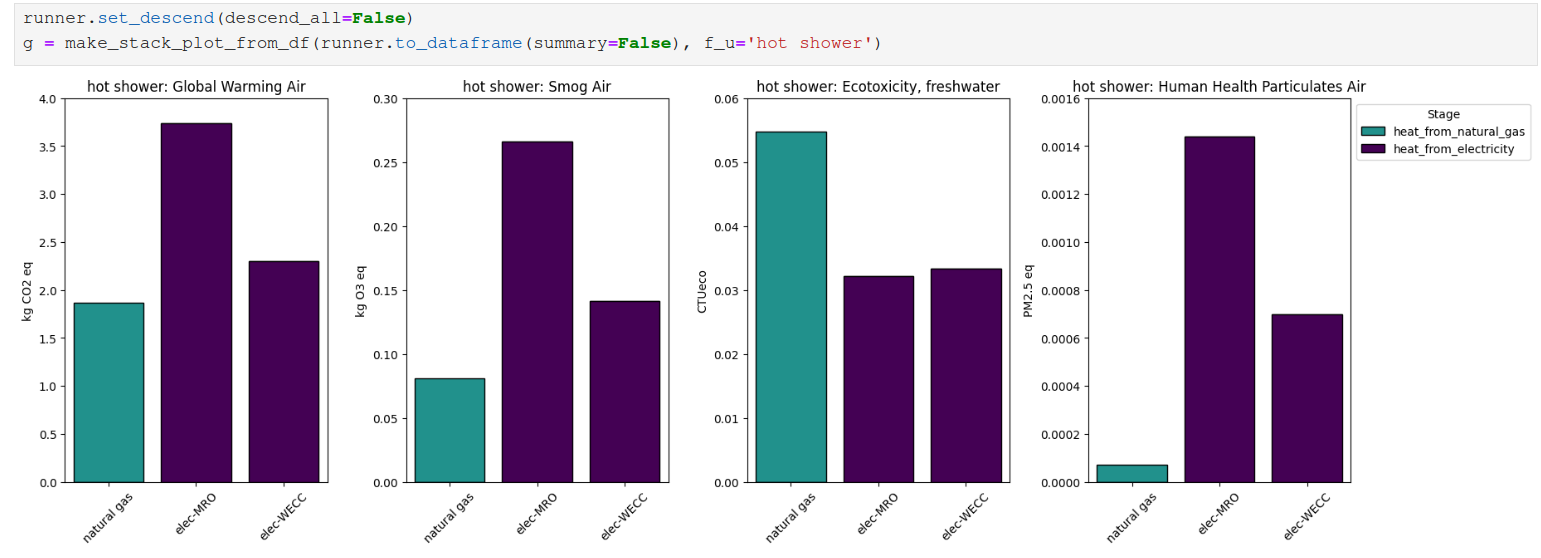
Aggregated results (descend_all=False)
Conclusion
Antelope software is focused on LCA foreground modeling, allowing an analyst to create a persistent, data-agnostic depiction of a physical system that can be linked by reference to external data sources, altered under different scenarios, and shared with different audiences in a data-free manner.